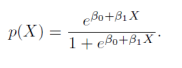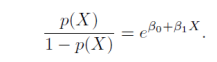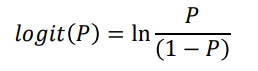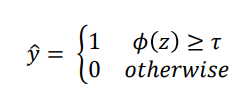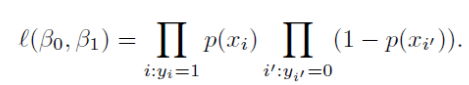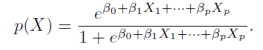선형 회귀 모델에서는 response variable Y가 qunatitative(양적 데이터:수치로 측정, 표현이 가능한 데이터)이라고 가정을 한다. 하지만 실제로는 다수의 상황에서는 qualitative하다.(질적 데이터: 수치로 측정 및 표시가 불가능한 자료, 성별이나 혈액형처럼 집단을 구분하는 변수)
이런 질적인 데이터를 예상하는 게 classification이라고 한다.
classification의 몇가지 예시이다.
선형회귀 설정에서 했던 것 처럼, Classification에서도 training observation들이 주어진다. (x1,y1),......,(xn,yn) 같은 주어진 데이터를 사용해서 분류기를 만드려고 한다. 물론 훈련데이터 뿐만 아니라, 아닌 데이터에도 적용이 되어야 할 것이다.
위 예시에서는 위에 주어진 신용카드 채무를 불이행 할지를 예측하는 모델을 만들고 싶다. 주어진 데이터로는 연소득, 월별 신용카드 잔액.
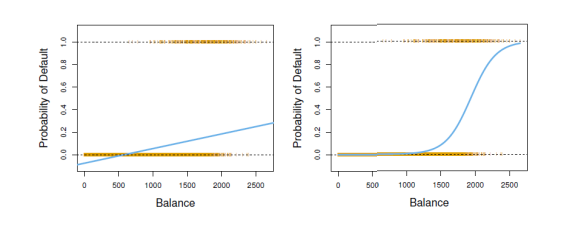
-이런 경우는 왜 선형 회귀를 적용시킬수 없을까?
예를 들어 응급실에서 환자의 증상에 따라 병명을 예측하는 모델을 만들고 싶다고 하자, 이 단순화된 예시에서는 3가지의 진단을 내릴수가 있다. stroke, drug overdose, epileptic seizure. 그렇다면 이 response variable Y 선형회귀시키기 위해서 숫자화를 시킨다고 하자.
이렇게 인코딩을 하면 어쩔수 없이 순서가 정해진다.
약물 과다복용이 뇌졸증과 간질 발작의 중간에 위치하면서 모델에서는 실제로는 아닌데 약물 과다복용, 뇌졸증사이의 차이가 약물 과다복용, 간질발작사이의 차이랑 같다고 취급하게 된다.
차라리 response variable이 2개라고 생각한다면 조금 더 선형회귀를 적용하기가 수월하다.
이런식으로 binary value를 가진다면, 선형회귀를 적용한다면 모델에서 Y^값이 0.5보다 크면 drug overdose의 확률이 더 크고, 0.5보다 작다면 stroke의 확률이 더 높다.
이렇게 범주형 변수를 연속형 변수로 변환시키는 것을 Dummy Variable,더미 변수라고 한다.
하지만 이런 적용에도 단점이 존재한다. 선형 회귀를 적용한다면 확률이 음수가 될수도 있고 1을 벗어나는 경우가 있다.
그래서 결국 선형회귀는 이런식의 데이터에는 사용하지 않는 것이 더 좋다.
-Logistic Regression
그러면 다시 신용카드 불이행 예시로 돌아가 보자. response variable은 두가지의 종류로 나누어진다. Yes, 아니면 No.
logistic regression은 직접적으로 response Y를 모델링 하기보다 Y가 특정 종류에 속할 확률을 구한다.
만약에 특정 잔고 balance가 주어진다면 조건부 확률을 통해서
Pr(default = Yes | balance)를 구할수가 있다. 확률값은 0과 1사이의 값을 가지기 때문에, 특정 확률 값의 기준을 정하고 Yes나 No를 예상을 할수가 있는 것이다.
그래서 p(X) = B0+ B1X 의 형식을 가지는 선형 회귀모델을 사용하기 보다 logistic function을 사용한다.
logistical function
이 함수를 그대로 사용하기에는 조금 어렵다.
그래서 odds(오즈비), logit function라고 하는 지표를 쓴다.
oddslogit function
이후 나온 확률 값을 Threshold function을 통해서 classification을 할수 있는 것이다.
모델을 피팅하기 위해서는 maximum likelihood라는 방법을 사용한다. 아까 봤었던 그래프와 같이 logistic regression은 S 형태의 그래프를 가진다. 예측 확률이 최대한 관측 데이터랑 같도록 B0이랑 B1(Coefficients)을 찾는게 목표니까 likelihood function을 쓰게 되는 것이다.
Likelihood(가능도, 우도)란, 데이터가 특정 분포로부터 만들어졌을(generate) 확률을 말한다.
-Estimating the Regression Coefficients
선형회귀에서 했던것 처럼 least square를 사용해서 계수를 가늠할수도 있지만 더 널리 사용되는 방법은 maximum likelihood를 사용한다.
실제로 logistic regression을 실행한 결과이다. balance의 계수가 0.0055인걸로 보아서 balance의 증가는 default의 증가와 연관되어 있다는 것을 확인할수가 있다.
-Making Predictions
이제 coefficient,계수가 구해졌으니까 balance가 주어진다면 우리는 default의 확률을 구할수가 있다.
한 개인의 balance가 $1000라면 default의 확률은 0.00576이다.
- Multiple Logistic Regression
그렇다면은 이제 yes,no라는 binary response를 multiple predictor을 사용하려고 한다.